IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR 2023)
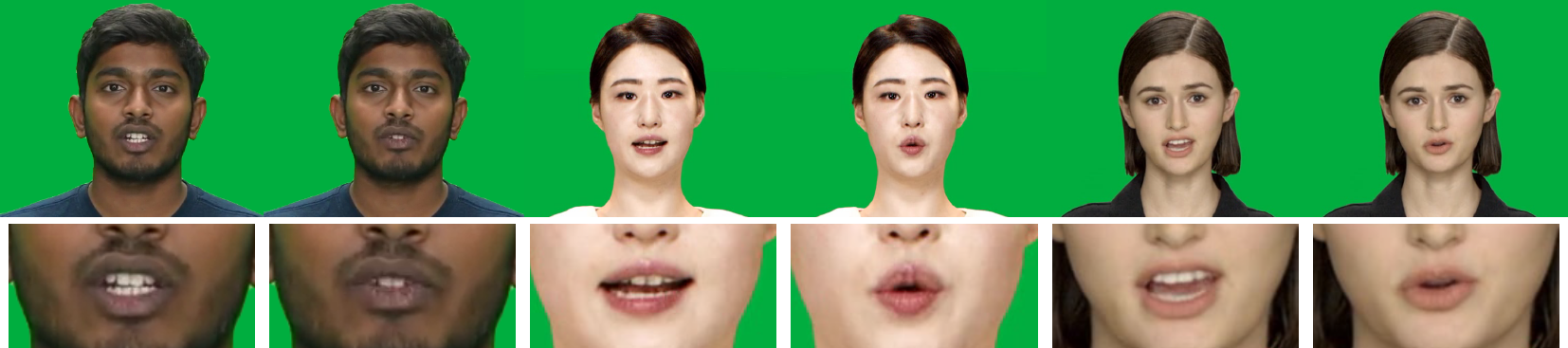
Over the last few decades, many aspects of human life have been enhanced with virtual domains, from the advent of digital assistants such as Amazon’s Alexa and Apple’s Siri to the latest metaverse efforts of the rebranded Meta. These trends underscore the importance of generating photorealistic visual depictions of humans. This has led to the rapid growth of so-called deepfake and talking head generation methods in recent years. Despite their impressive results and popularity, they usually lack certain qualitative aspects such as texture quality, lips synchronization, or resolution, and practical aspects such as the ability to run in real-time. To allow for virtual human avatars to be used in practical scenarios, we propose an end-to-end framework for synthesizing high-quality virtual human faces capable of speech with a special emphasis on performance. We introduce a novel network utilizing visemes as an intermediate audio representation and a novel data augmentation strategy employing a hierarchical image synthesis approach that allows disentanglement of the different modalities used to control the global head motion. Our method runs in realtime, and is able to deliver superior results compared to the current state-of-the-art.